population <-read_csv("https://soc114.github.io/data/baseball_population.csv")
# A tibble: 944 × 6
player salary position team team_past_record team_past_salary
<chr> <dbl> <chr> <chr> <dbl> <dbl>
1 Bumgarner, Madison 21882892 LHP Arizona 0.457 2794887.
2 Marte, Ketel 11600000 2B Arizona 0.457 2794887.
3 Ahmed, Nick 10375000 SS Arizona 0.457 2794887.
4 Kelly, Merrill 8500000 RHP Arizona 0.457 2794887.
5 Walker, Christian 6500000 1B Arizona 0.457 2794887.
# ℹ 939 more rows
A data example
player is the player name
salary is the 2023 salary
position is the position played (e.g., LHP for left-handed pitcher)
team is the team name
team_past_record was the team’s win percentage in the previous season
team_past_salary was the team’s average salary in the previous season
A binary outcome
You see a player’s salary
Are they a catcher?
position == "C"
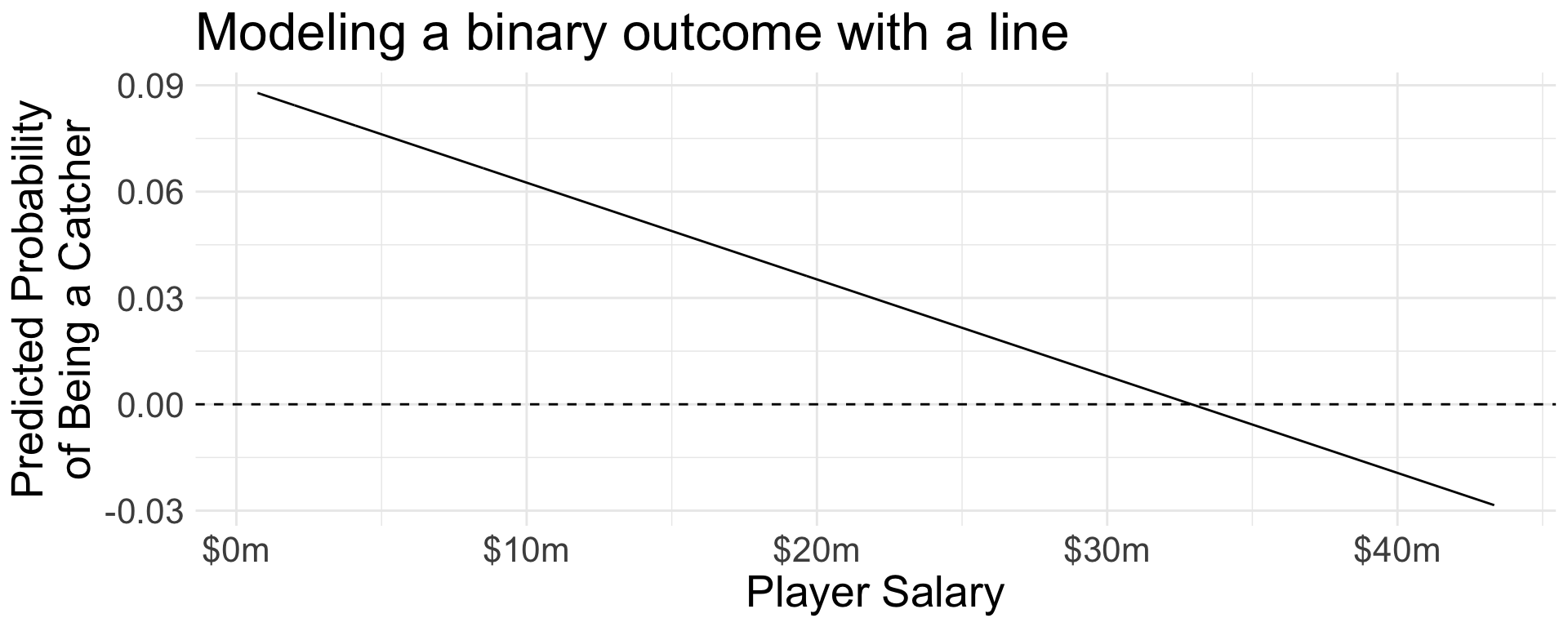
Linear probability model
We can model with lm() for a linear fit.
ols_binary_outcome <-lm( position =="C"~ salary,data = population)
Code
population |>mutate(yhat =predict(ols_binary_outcome)) |>ggplot(aes(x = salary, y = yhat)) +geom_line() +geom_hline(yintercept =0, linetype ="dashed") +scale_x_continuous(name ="Player Salary",labels =label_currency(scale =1e-6, suffix ="m") ) +scale_y_continuous(name ="Predicted Probability\nof Being a Catcher" ) +ggtitle("Modeling a binary outcome with a line")
Goal: Avoid illogical predictions
In OLS, there is a linear predictor \[
\mu = \beta_0 + X_1\beta_1 + X_2\beta_2 + \cdots
\] that can take any numeric value. Possibly \(\mu <0\) or \(\mu > 1\).
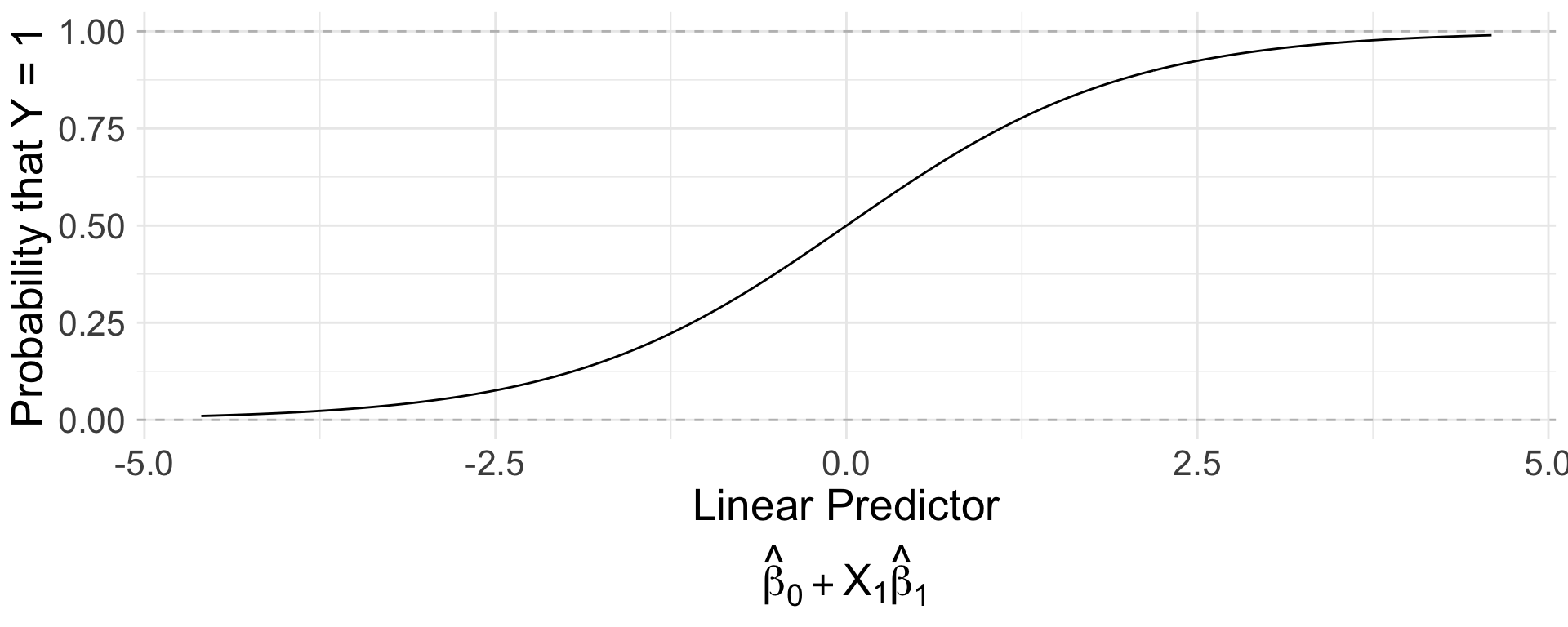
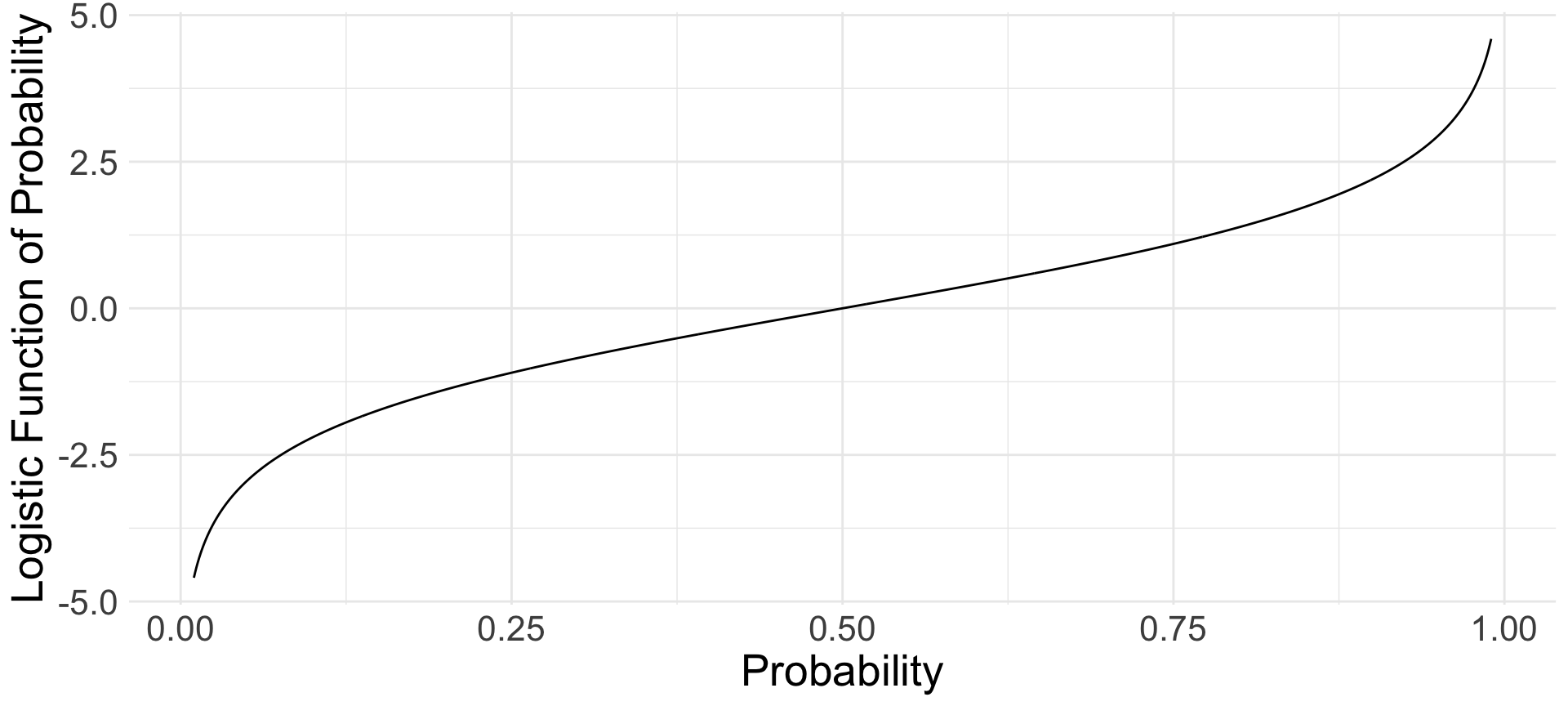
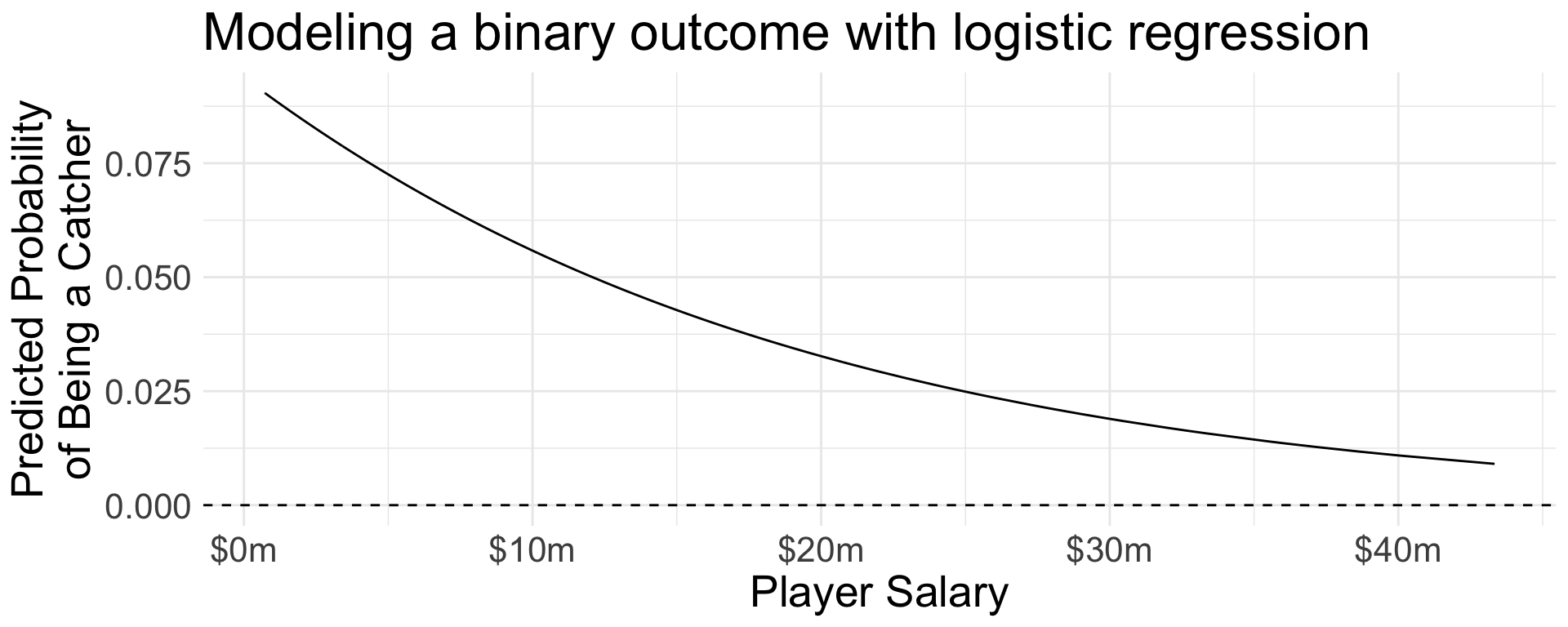
From \(\mu\) to \(\pi\)
Logistic regression passes the linear predictor \[\mu = \beta_0 + X_1\beta_1 + X_2\beta_2 + \cdots\] through a nonlinear function to force it between 0 and 1.