Exchangeability
Causal effects involve both factual and counterfactual outcomes, yet data that we can observe involve only factual outcomes. To learn about causal effects from data that can be observed requires assumptions about the data that are not observed. This page introduces exchangeability, which is an assumption that can identify causal effects.
Exchangeability in simple random samples
The figure below illustrates a population of 6 people. Each person has an outcome \(Y_i\), which for example might be that person’s employment at age 40. A researcher draws a random sample without replacement with equal sampling probabilities and records the sampled outcomes. The researcher uses the average of the sampled outcomes as an estimator for the population mean.

Why do probability samples like this work? They work because selection into the sample (\(S = 1\)) is completely randomized and thus independent of the outcome \(Y\). In other words, the people who are sampled (\(S = 1\)) and the people who are unsampled (\(S = 0\)) have the same distribution of outcomes (at least in expectation over samples). We might say that the sampled and the unsampled units are exchangeable in the sense that they follow the same distribution in terms of \(Y\). In math, exchangeable sampling can be written as follows.
\[ \underbrace{Y}_\text{Outcome}\quad \underbrace{\mathrel{\unicode{x2AEB}}}_{\substack{\text{Is}\\\text{Independent}\\\text{of}}} \quad \underbrace{S}_{\substack{\text{Sample}\\\text{Inclusion}}} \]
Exchangeability holds in simple random samples because sampling is completely independent of all outcomes by design. In other types of sampling, such as convenience samples that enroll anyone who is interested, exchangeability may hold but is far from guaranteed. Perhaps people who are employed are more likely to answer a survey about employment, so that the employment rate in a convenience sample might far exceed the population mean employment rate. Exchangeability is one condition under which reliable population estimates can be made from samples, and probability samples are good because they make exchangeability hold by design.
Exchangeability in randomized experiments
The figure below illustrates our population if they all enrolled in a hypothetical randomized experiment. In this experiment, we imagine that each unit is either randomized to attain a four-year college degree (\(A = 1)\) or to finish education with a high school diploma (\(A = 0\)).
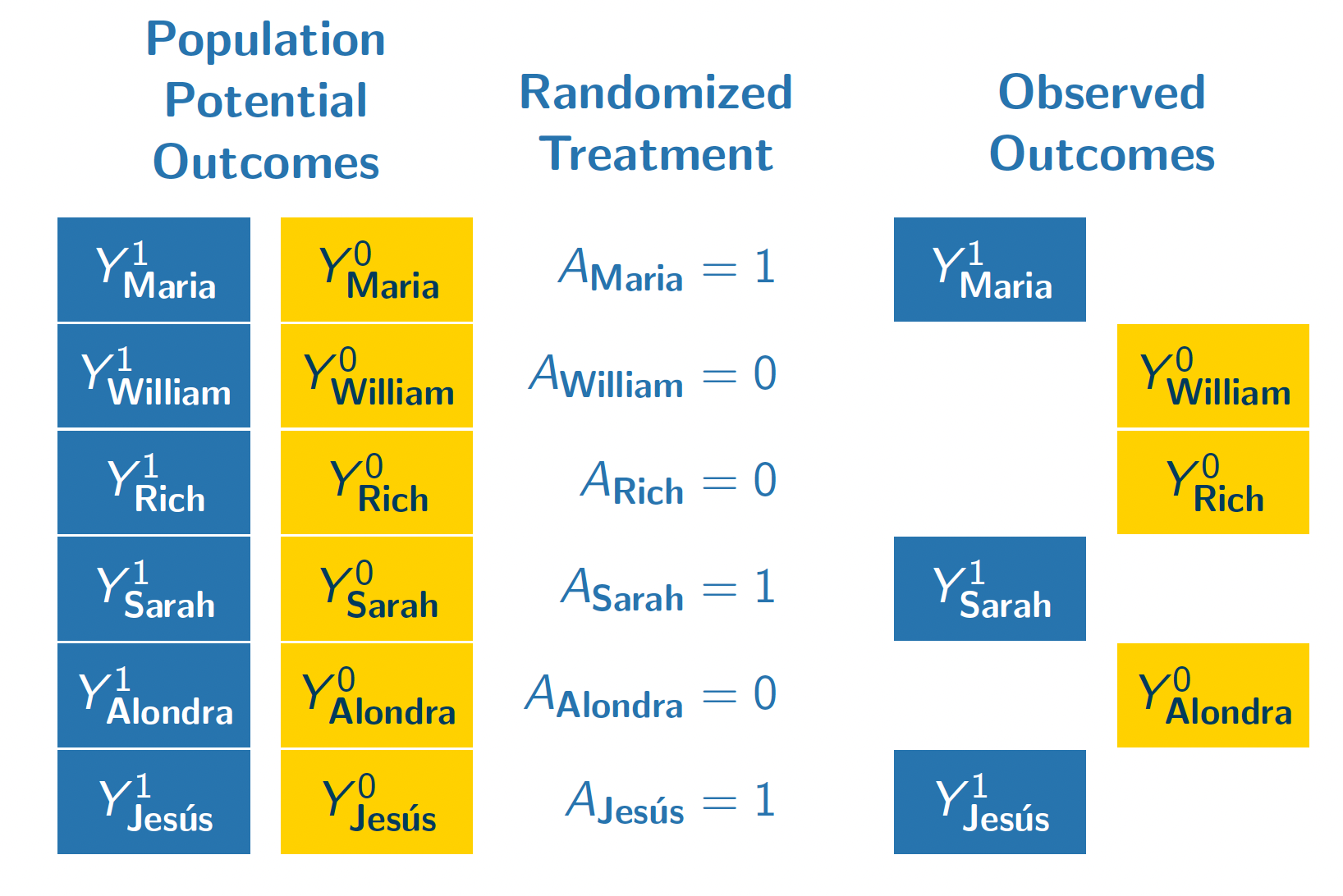
In this randomization, Maria, Sarah, and Jes'us were randomized to attain a four-year college degree. We observe their outcomes under this treatment condition (\(Y^1\)). Because treatment was randomized with equal probabilities, these three units form a simple random sample from the full population of 6 people. We could use the sample mean of \(Y^1\) among the treated units (Maria, Sarah, Jes'us) as an estimator of the population mean of \(Y^1\) among all 6 units.
William, Rich, and Alondra were randomized to finish their education with a high school diploma. We see their outcomes under this control condition \(Y^0\). Their treatment assignment (\(A = 0\)) is analogous to being sampled from the population of \(Y^0\) values. We can use their sample mean outcome as an estimator of the population mean of \(Y^0\).
Formally, we can write the exchangeability assumption for treatment assignments as requiring that the set of potential outcomes are independent of treatment assignment.
\[ \underbrace{\{Y^1,Y^0\}}_{\substack{\text{Potential}\\\text{Outcomes}}}\quad\underbrace{\mathrel{\unicode{x2AEB}}}_{\substack{\text{Are}\\\text{Independent}\\\text{of}}}\quad \underbrace{A}_\text{Treatment} \] Exchangeability holds in randomized experiments because treatment is completely independent of all potential outcomes by design. In observational studies, where treatment values are observed but are not assigned randomly by the researcher, exchangeability may hold but is far from guaranteed. In the coming classes, we will talk about generalizations of the exchangeability assumption that one can argue might hold in some observational settings.
Causal identification
A population-average causal effect could take many possible values. Using data alone, it is impossible to identify which of these many possible values is the correct one. By pairing data together with causal assumptions, however, one can identify the average causal effect by equating it with a statistical quantity that only involves observable random variables.
Causal identification. A mathematical proof linking a causal estimand (involving potential outcomes) to a statistical quantity involving only factual random variables.
In a randomized experiment, the average causal effect is identified by the assumptions of consistency and exchangeability. A short proof can yield insight about the goals and how these assumptions are used.
\[ \begin{aligned} &\overbrace{\text{E}\left(Y^1\right) - \text{E}\left(Y^0\right)}^{\substack{\text{Average}\\\text{causal effect}\\\text{(among everyone)}}} \\ &= \text{E}\left(Y^1\mid A = 1\right) - \text{E}\left(Y^0\mid A = 0\right) &\text{by exchangeability}\\ &= \underbrace{\text{E}\left(Y\mid A = 1\right)}_{\substack{\text{Mean outcome}\\\text{among the treated}}} - \underbrace{\text{E}\left(Y\mid A = 0\right)}_{\substack{\text{Mean outcome}\\\text{among the untreated}}} &\text{by consistency} \end{aligned} \]
The proof begins with the average causal effect and equates it to a statistical estimand: the mean outcome among the treated minus the mean outcome among the untreated. The first quantity involves potential outcomes (with superscripts), whereas the last quantity involves only factual random variables.
The exchangeability assumption allows us to move from the first line to the second line. Under exchangeability, the mean outcome that would be realized under treatment (\(\text{E}(Y^1)\)) equals the mean outcome under treatment among those who were actually treated (\(\text{E}(Y^0)\)). Likewise for outcomes under no treatment. This line is true because the treated (\(A = 1\)) and the untreated (\(A = 0\)) are both simple random samples from the full population.
The consistency assumption allows us to move from the second line to the third. Among the treated, (\(A = 1\)), the outcome that is realized is \(Y = Y^1\). Among the untreated (\(A = 0\)), the outcome that is realized is \(Y = Y^0\). Under the assumption that factual outcomes are consistent with the potential outcomes under the assigned treatment, the second line equal the third.
Something nice about a causal identification proof is that there is no room for error: it is mathematically true that the premise and the assumptions together yield the result. As long as the assumptions hold, the statistical estimand equals the causal estimand. Causal inference thus boils down to research designs and arguments that can lend credibility to the assumptions that let us draw causal claims from data that are observed.